Uruchomienie modeli językowych lokalnie wielu developerom wciąż kojarzy się z zabawą wymagającą sporo wiedzy i zachodu. Tymczasem ekosystem narzędzi wokół open source’owych modeli przyspieszył na tyle, że większość tej pracy mogą za nas wykonać gotowe aplikacje. Pod względem wydajności i prędkości działania modele lokalne nie są dziś może realną alternatywą dla coraz droższych modeli chmurowych, jednak jeśli chodzi o wykonywanie mniej skomplikowanych zadań, mogą dowieść swojej skuteczności. Nie zawsze przecież potrzebujemy od razu najwyższych wersji Claude’a, GPT, Gemini czy Groka. Jest cała kategoria zadań, przy których słabsze, lokalne modele sprawdzą się wystarczająco dobrze. Poniżej przedstawiam ogólną koncepcję odpalenia lokalnego modelu. To prostsze, niż myślisz!
Sprzęt do grania nada się też do generatywnej AI
Przede wszystkim, przyda się nam co najmniej średniej klasy komputer gamingowy. Do w miarę wydajnej pracy z modelem potrzebujemy bowiem sensownej karty graficznej, której procesor i pamięć znacznie lepiej dają sobie radę z przetwarzaniem tokenów, niż RAM komputera. Istotne jest zatem, aby model zmieścił się w VRAM. Jako praktyczna wskazówka: skwantyzowany model 7B (np. w formacie Q4_K_M) zajmuje ok. 4–5 GB VRAM i bez problemu działa na kartach z 6–8 GB; model 13B potrzebuje ok. 7–9 GB (do komfortowej pracy wystarczy 12 GB), a modele 30B i większe zazwyczaj wymagają 20 GB VRAM lub więcej. Modele 70B na konsumenckim GPU są możliwe wyłącznie przy częściowym odciążaniu do RAM‑u hosta (CPU offloading), co jednak wyraźnie spowalnia generację. Zatem można w dużym uproszczeniu przyjąć, że im więcej pamięci, tym lepiej.
LM Studio
LM Studio to wygodna nakładka na modele, która zajmuje się ich pobieraniem, uruchamianiem, kwantyzacją i wystawianiem serwera API.
- Windows: pobierz instalator .exe ze strony lmstudio.ai, uruchom go i postępuj zgodnie z kreatorem instalacji.
- macOS: pobierz plik .dmg i przeciągnij aplikację do folderu Applications.
- Linux: pobierz plik AppImage, oznacz go jako wykonywalny i uruchom.
Cała instalacja sprowadza się do kilku kliknięć – instalatory dla wszystkich platform znajdziesz na oficjalnej stronie pobierania LM Studio.
Pobieranie modelu w LM Studio
Po uruchomieniu aplikacji przechodzisz do zakładki Model Search i korzystasz z wewnętrznej wyszukiwarki, która integruje się z Hugging Face.
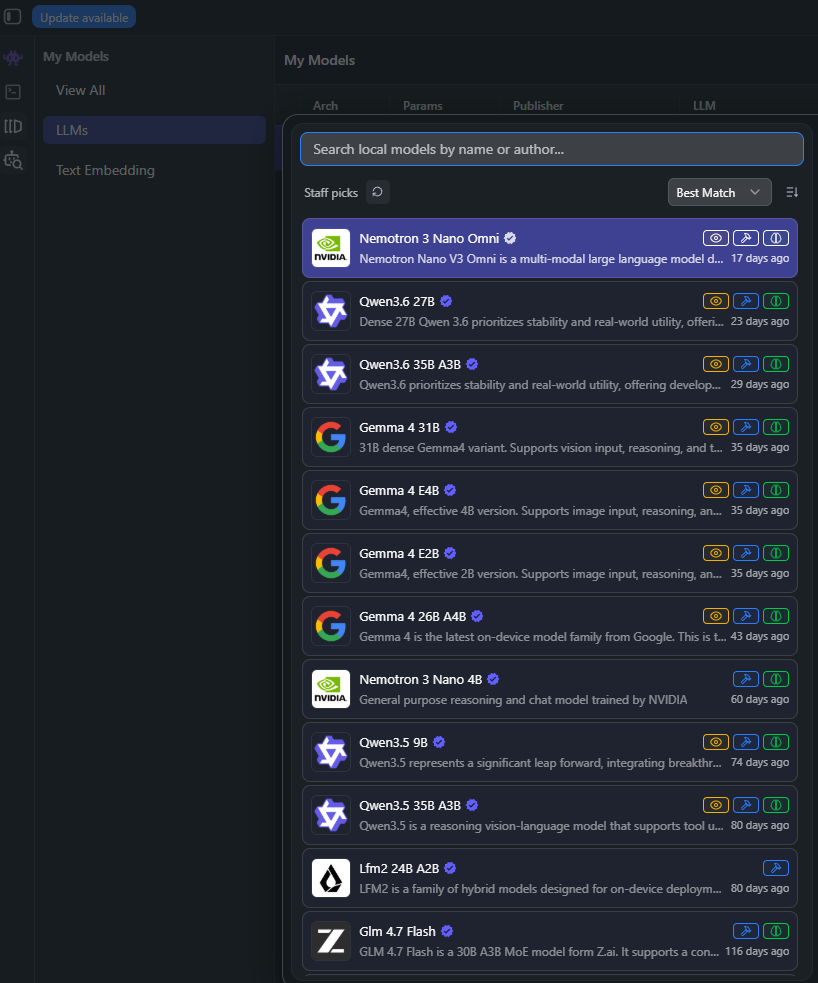
Klikasz wybrany model, dostosowujesz opcje, np. pobierasz odpowiednią kwantyzację (np. Q4_K_M, Q5, Q8) i LM Studio automatycznie umieszcza go w lokalnym repozytorium. Nie trzeba niczego ręcznie kopiować ani konfigurować. Po prostu – wybierasz i instalujesz.
Czatowanie lokalnie
Po zainstalowaniu model jest dostępny do użycia. W zakładce Chat możesz otworzyć nową konwersację, wybrać pobrany model z dropdownu na górze ekranu, zdefiniować parametry, takie jak okno kontekstowe czy temperaturę, wczytać model do pamięci i zacząć rozmowę. Osiągnięcie satysfakcjonujących rezultatów może wymagać nieco prób i błędów. Jeśli możesz, ustaw np. model na niższą kwantyzację – poprawia to szybkość i obniża wymagania sprzętowe. Nie odbywa się oczywiście bez wad. Niższa kwantyzacja to mniej „inteligentne” odpowiedzi.
Dostęp do serwerów MCP
Jeżeli chcesz, aby lokalny model pełnił funkcje agentowe, LM Studio obsługuje integrację z MCP (Model Context Protocol). Dzięki temu model może mieć dostęp do narzędzi serwerowych, API i usług lokalnych, co otwiera drogę do bardziej zaawansowanych automatyzacji.
Programowanie z użyciem lokalnego modelu: LM Studio + Zed jako przykładowa konfiguracja
No dobrze, ale czy da się w ten sposób programować? Otóż, da się, choć nie przy użyciu dowolnego IDE. LM Studio oferuje możliwość wystawienia lokalnego serwera API zgodnego z API OpenAI, pozwalającego na pracę z zewnętrznymi narzędziami, np. edytorem kodu.
Jako edytora kodu możemy użyć Zed. Zed to nowoczesny i bardzo wydajny program napisany w Rust, stworzony przez część dawnego zespołu stojącego za edytorem Atom. Jego głównymi zaletami są błyskawiczne działanie, wbudowana obsługa pracy grupowej w czasie rzeczywistym oraz natywna integracja z modelami językowymi – bez potrzeby instalowania dodatkowych wtyczek. Zed jest dostępny na macOS, Linux i Windows.
Po instalacji edytora Zed przechodzisz do okna czatu wbudowanego w edytor i w menu wyboru modelu wybierasz Configure. Następnie z listy potencjalnych dostawców LLM Providers wybierasz LM Studio.
Wróć teraz do LM Studio. Zakładam, że masz je uruchomione. Przejdź zatem do zakładki Developer i uruchom serwer przełącznikiem w lewym górnym rogu. Obok niego znajdziesz przycisk Server Settings. W ustawieniach serwera możesz zmienić konfigurację. Możesz, dla uproszczenia, wyłączyć autoryzację, aby Zed połączył się z twoim serwerem lokalnym bez konieczności uwierzytelniania tokenu.
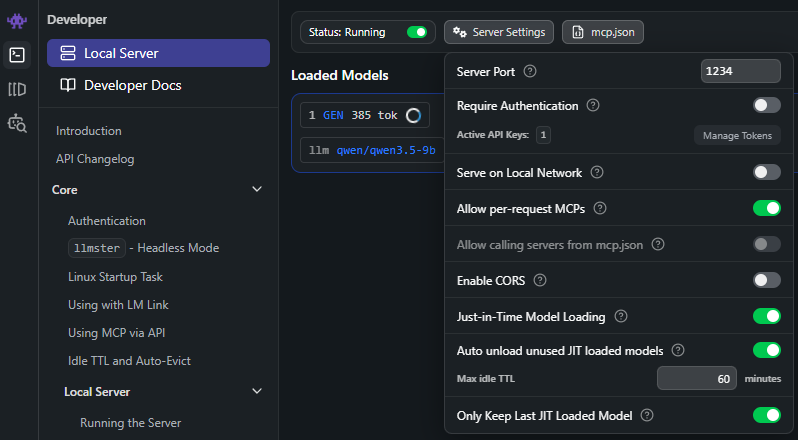
Dalej na prawo znajdziesz też przycisk Load Models, który otwiera okno konfiguracji dostępnych modeli. Tam możesz np. dostosować parametry modelu, aby wpłynąć na jakość pracy.
W porządku, wróćmy do Zeda. Będąc na ekranie konfiguracji dostawców LLM w opcji LM Studio wpisz adres URL serwowanego API. W moim przypadku było to:
http://localhost:1234/api/v0Następnie podajesz klucz API ustawiony w LM Studio albo pozostawiasz pole niewypełnione, jeśli wyłączyłeś/aś autoryzację w LM Studio. Następnie klikasz na przycisk Connect i jeśli wszystko poszło ustawiono prawidłowo, Zed podłączy się do serwowanego przez ciebie lokalnego API.
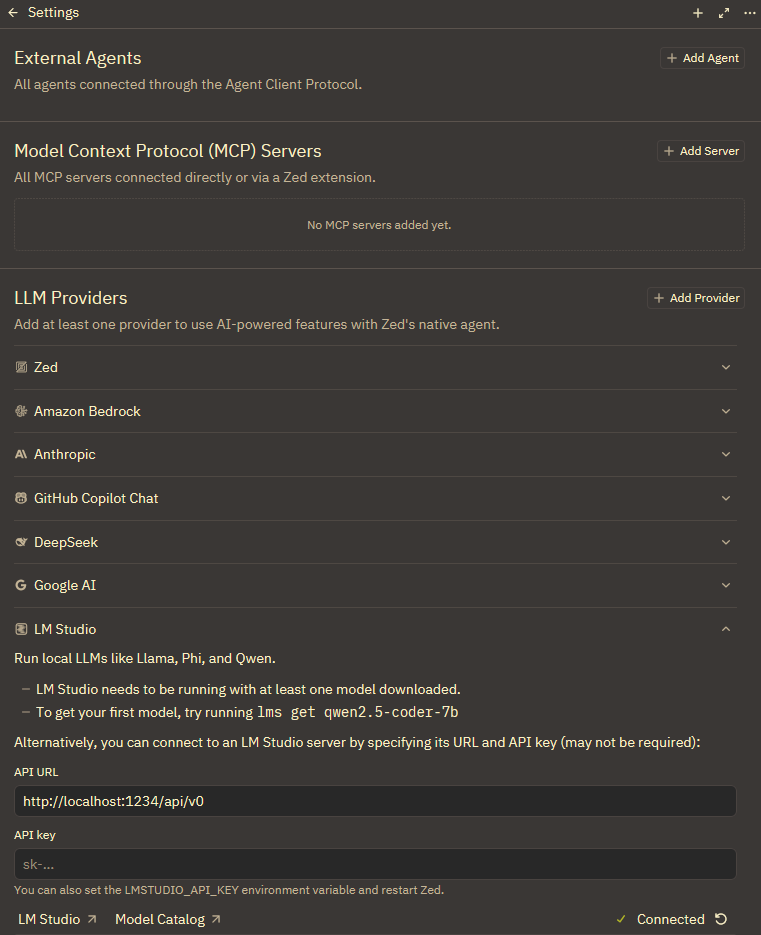
Po tym kroku możesz wybierać dowolny pobrany model z opcji wyboru modelu w czacie Zed i używać go do generowania kodu, refaktoryzacji czy pisania dokumentacji. Czyli – robienia tego wszystkiego, z czym wiąże się kodowanie do spółki z agentem AI.
Używać, czy nie używać?
Powiedzmy sobie wprost, lokalny model zawsze będzie wolniejszy od modeli chmurowych, chyba że zupełnie przypadkiem dysponujesz superkomputerem. Wydajność jest czysto sprzętowa: liczba rdzeni, przepustowość pamięci, VRAM i taktowanie GPU. Do eksperymentów, prostych integracji, analizy kodu i krótkich promptów może to być wystarczające. Do zadań wymagających dużych kontekstów lub perfekcyjnej jakości – najprawdopodobniej będzie zdecydowanie zbyt mało wydajne.
W mojej opinii jednak, lokalny model nie jest konkurencją dla usług chmurowych oferowanych przez Anthropic, OpenAI, Google’a czy xAI. Ma jednak swoje bardzo konkretne zalety: pełną prywatność danych i zerowy koszt użytkowania. W czasach, gdy ceny modeli chmurowych stale rosną, co szczególnie widać w przypadku Anthropic (Opus potrafi pożreć tygodniową kwotę w parę godzin), rośnie znaczenie tanich bądź lokalnych alternatyw. Warto je poznać, bo w wielu scenariuszach okazują się zaskakująco praktyczne. Lokalna AI nie zastąpi ci chmury, ale świetnie ją uzupełni i da ci pełną kontrolę nad tym, jak i gdzie przetwarzane są twoje dane.
Fot. fgnopporn/Adobe Stock + modyfikacja w Nano Banana